simple note taking
I was just watching Prot's explanation of his new package denote, a very elegant note-taking system with a stress on simplicity and, as the author puts it, low-tech requirements. Now, those are excellent qualities in my book, and i think i'd quickly become a denote user if it weren't for the fact that i already have a homegrown set of utilities following a similar philosophy. Inevitably, they differ in some details, as is to be expected from software that has grown with me, as Prot's with him, during more than a decade, but they are similar in important ways.
I've had in mind writing a brief note on my notes utilities for a while, so i guess this is a good time for it: i can, after showing you mine, point you to a polished package following a similar philosophy and sidestep any temptation of doing anything similar with my little functions :)
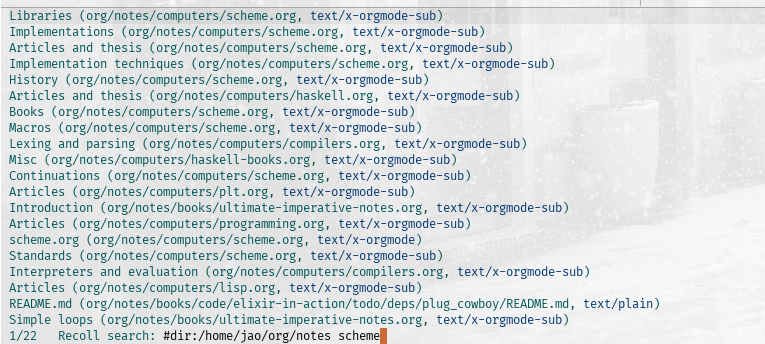
As you'll see in a moment, in some ways, my note taking system is even simpler than Prot's, while in others i rely on more sophisticated software, essentially meaning that where denote is happy to use dired and filenames, i am using grep over the front-matter of the notes. So if you loved the filename-as-metadata idea in denote, you can skip the rest of this post!
These are the main ideas around which i built my note-taking workflow:
- Personally, i have such a dislike for non-human readable identifiers, that
i cannot even stand those 20221234T142312 prefixes (for some reason, i
find them quite hard to read and distracting). When i evolved my notes
collection, i wanted my files to be named by their title and nothing more.
I am also pretty happy to limit myself to org-mode files. So i wanted a
directory of (often short) notes with names like
the-lisp-machine.org,david-foster-wallace.orgorcombinator-parsing-a-short-tutorial.org.1 - I like tags, so all my notes, besides a title, are going to have attached a list of them (denote puts them in the filename and inside the file's headers; i'm content with the latter, because, as you'll see in a moment, i have an easy way of searching through that contents).
- I'm not totally averse to hierarchies: besides tagging, i put my notes in a subdirectory indicating their broad category. I can then quickly narrow my searches to a general theme if needed2.
- As mentioned, i want to be able to search by the title and tag (besides
more broadly by contents) of my notes. Since that's all information
available in plain text in the files,
grepand family (via their emacs lovely helpers) are all that is needed; but i can easily go a step further and use other indexers of plain text like, say, recoll (via my consult-recoll package). - It must be easy to quickly create notes that link to any contents i'm
seeing in my emacs session, be it text, web, pdf, email, or any other.
That comes for free thanks to org and
org-capture. - I want the code i have to write to accomplish all the above to be short and sweet, let's say well below two hundred lines of code.
Turns out that i was able to write a little emacs lisp library doing all the
above, thanks to the magic of org-mode and consult: you can find it over at my
repo by the name of jao-org-notes.el. The implementation is quite simple and
is based on having all note files in a parent directory (jao-org-notes-dir)
with a subfolder for each of the main top-level categories, and, inside each
of them, note files in org mode with a preamble that has the structure of this
example:
#+title: magit tips #+date: <2021-07-22 Thu> #+filetags: git tips
The header above corresponds to the note in the file emacs/magit-tips.org.
Now, it's very easy to write a new command to ask for a top-level category and
a list of tags and insert a header like that in a new file: it's called
jao-org-notes-open-or-create in my little lib, and with it one can define a
new org template:
("N" "Note" plain (file jao-org-notes-open-or-create) "\n- %a\n %i" :jump-to-captured t)
that one can then add to org-capture-templates (above, i'm using "N" as its
shortcut; in the package, this is done by jao-org-notes-setup, which takes the
desired shortcut as a parameter). I maintain a simple list of possible tags
in the variable jao-org-notes--tags, whose value is persisted in the file
denoted by the value jao-org-notes-tags-cache-file, so that we can remember
newly-added tags; with that and the magic of emacs's completing read, handling
tags is a breeze.
Now for search. These are text files, so if i want to search for contents, i
just need grepping, for instance with M-x rgrep or, even better, M-x
consult-ripgrep. That is what the command jao-org-notes-grep does.
But it is also very useful to be able to limit searches to the title and tags
of the notes: that's what the command jao-org-notes-open does using consult
and ripgrep by the very simple device of searching for regular expressions in
the first few lines of each file that start with either #+title: or
#+filetags: followed by the terms we're looking for. That's something one
could already do with rgrep alone; what consult adds to the party is the
ability of displaying the matching results nicely formatted:

Links between notes are simply org file: links, and having a simple
"backlinks" command is, well, simple if you don't want anything fancy3.
A command to insert a new link to another note is so boring to almost not
meriting mention (okay, almost: jao-org-notes-insert-link).
And that's about it. With those simple commands and in about 160 lines of code i find myself comfortably managing plain text notes, and easily finding contents within them. I add a bit of icing by asking Recoll to index my notes directory (as well as my email and PDFs): it is clever enough to parse org files, and give you back pointers to the sections in the files, and then issue queries with the comfort of a consult asynchronous command thanks to consult-recoll (the screenshot in the introduction is just me using it). It's a nice use case of how having little, uncomplicated packages that don't try to be too sophisticated and center on the functionality one really needs makes it very easy to combine solutions in beatiful ways4.
Footnotes:
I also hate with a passion those :PROPERTIES: drawers and other
metadata embellishments so often used in org files, and wanted to avoid them
as much as possible, so i settled with the only mildly annoying #+title and
friends at the beginning of the files and nothing more. The usual caveat that
that makes it more difficult to have unique names has proven a non-problem to
me over the years.
Currently i use work, books, computers, emacs, letters, maths, and
physics: as you see, i am not making a great effort on finding the perfect
ontology of all knowledge; rather, i just use the first broad breakdown of the
themes that interest me most at the moment.
Just look for the regular expression matching "[[file:" followed by the name of the current file. I find myself seldom needing this apparently very popular functionality, but it should be pretty easy to present the search results in a separate buffer if needed.
Another example would be how easy it becomes to incorporate web contents nicely formatted as text when one uses eww as a browser. Or how how seamless it is taking notes on PDFs one's reading in emacs, or even externally zathura (that's for a future blog post though! :)).
